アプリ関連ニュース
Flutterで生体認証等を行えるライブラリ local_auth
tanaka at 2021年12月22日 10:00:00
- 2021年12月21日
- 技術情報, Web Service
PHP Zipper package using PHP ZipArchive
Today I would like to share a PHP package that I wrote last weekend. This was written to make Zipping processes easily and automatically using PHP ZipArchive. Let’s take a look.
First of all, install the package with composer.
composer require waithaw/phpzipperAfter creating Zip Object, you can use the following methods.
include_once "vendor/autoload.php";
use WaiThaw\PhpZipper\Zip;
$zip = new Zip();These are the example file lists.
$filelists= [
'D:\testfolder\test1.txt',
'D:\testfolder\test1folder\test2.txt'
];
$file = 'D:\testfolder\test1.txt';Creating a Zip file from Single file or multiple files
You can create an archive zip file from single file or multiple files.
1st parameter – output zip path
2nd parameter – a file or files to be zipped
3rd parameter – setting a password
- Zipping a single file or mutiple files with no password
$zip->createFromFiles('backup.zip', $file);
//OR
$zip->createFromFiles('backup.zip', $filelists);
- Zipping a single file or mutiple files with password
$zip->createFromFiles('backup.zip', $file ,'password');
//OR
$zip->createFromFiles('backup.zip', $filelists,'password');Creating a Zip file from a directory including sub directories.
You can archive all files and subfolders in a directory into a zip file.
- Zipping a directory with no password
$zip->createFromDir('backup.zip','D:\testfolder');- Zipping a directory with password
$zip->createFromDir('backup.zip','D:\testfolder','password');Extracting a simple or password-protected zip file
- Extracting a simple zip file.
$zip->extractTo('backup.zip','D:\outputpath');- Extracting a password-protected zip file
$zip->extractTo('backup.zip','D:\outputpath', 'password');Downloading zip files
You can download the zip file at once archiving.
$zip->createFromFiles('backup.zip', $file)->download();
$zip>createFromDir('backup.zip','D:\testfolder')->download();And you can also delete the zip file after downloaded, by passing ‘delete’ string in download() method.
$zip->createFromFiles('backup.zip', $file)->download('delete');
$zip>createFromDir('backup.zip','D:\testfolder')->download('delete');
This is all for now. I will continue to update this package for more features and details.
Hope you enjoy that.
By Asahi
waithaw at 2021年12月21日 10:00:00
- 2021年12月20日
- 技術情報
Github Wrapped
Developers normally code a lot just for a month but think for a year. If we want to see our history of our git commits, PRs, reviews etc through out a year , there is a newly service website called Github Wrapped.
You just need to login your github account and go to this website.
You may be asked for authorization to use the website from your Github account. After giving authorization this home screen will appear. I used my personal Github account for testing purpose.
Then you just need to go on by clicking the play button, these are my results.
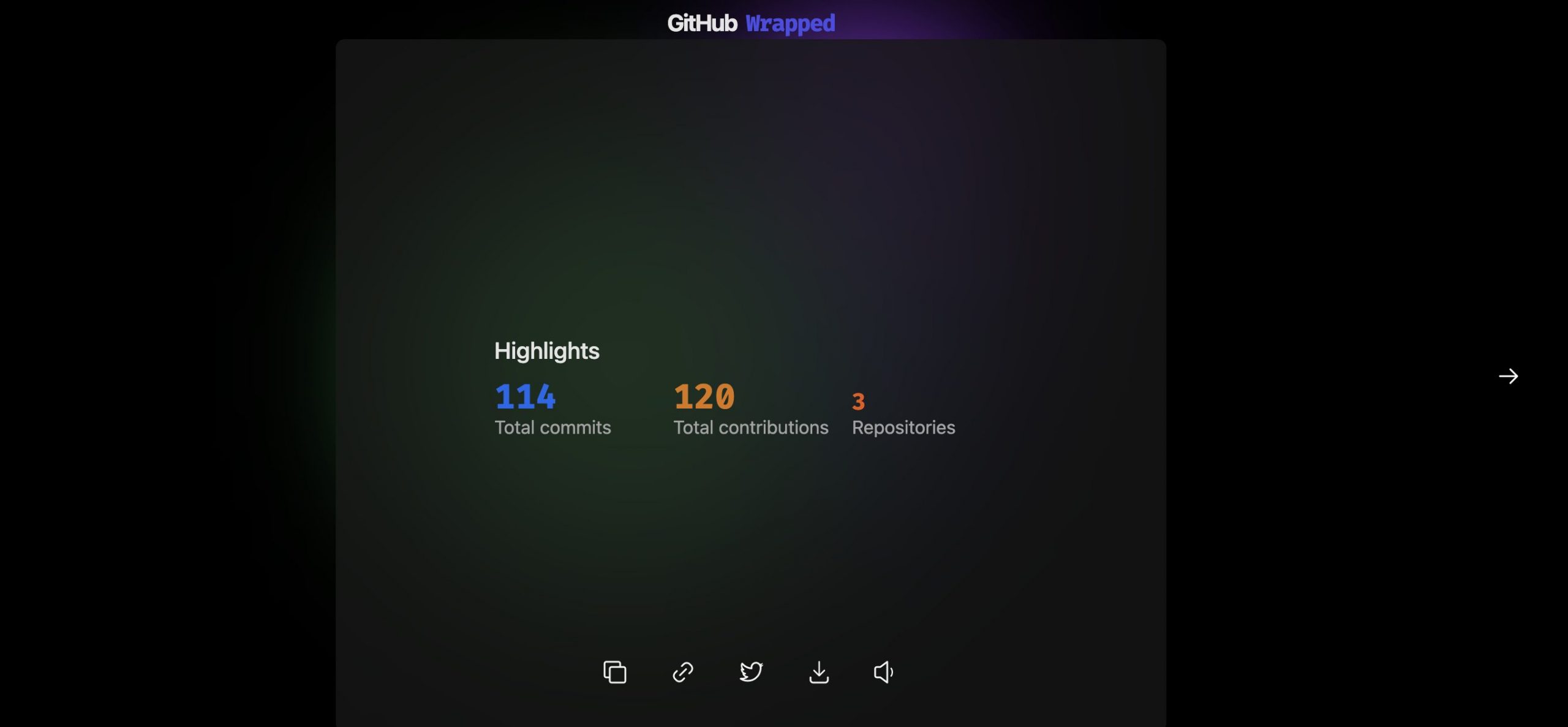
You will also see a bunch of your activities like followers, stars etc.
But for the final result, you will get a pretty home page for your activity history through out the year (2021).
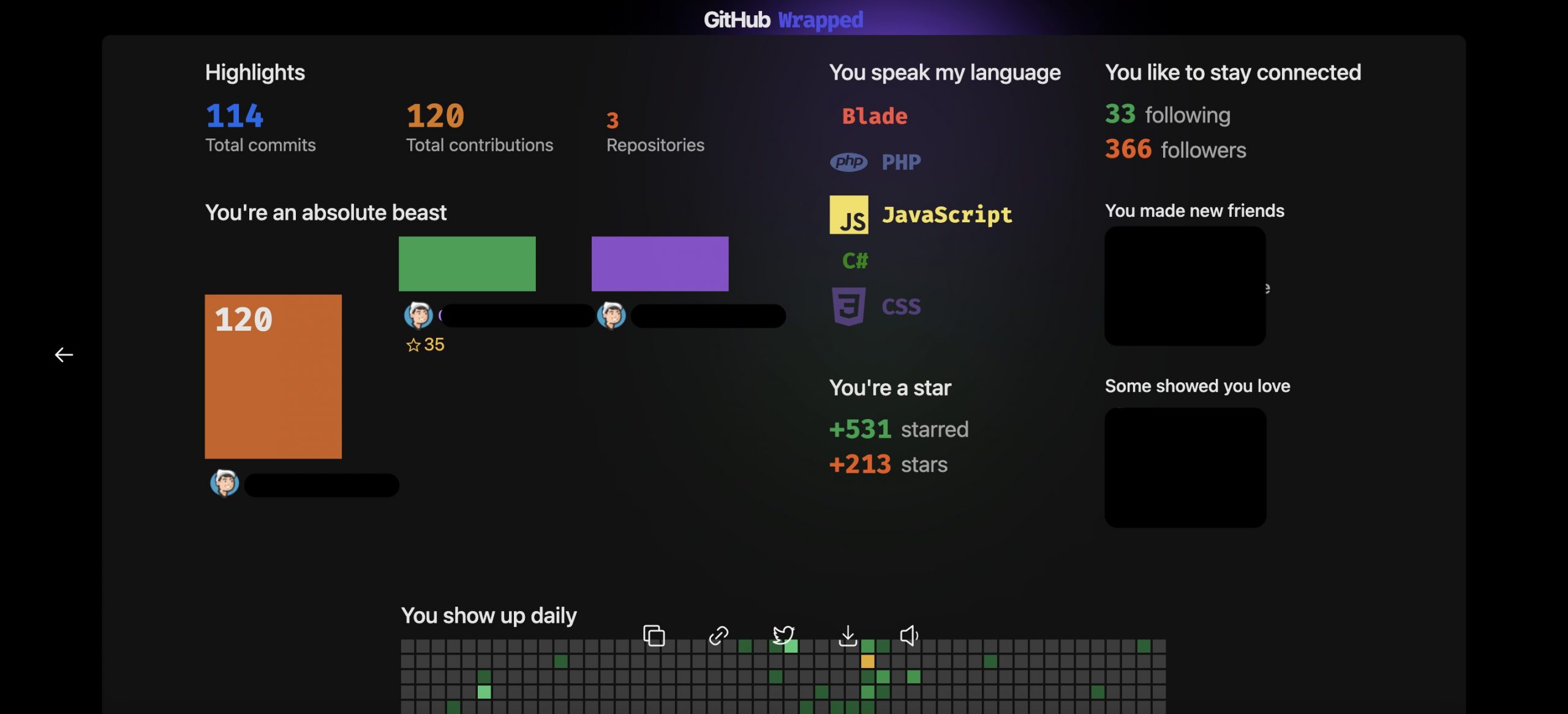
You can even copy/download your final image to save on your disk or share on twitter. I think this is a nice and pretty way to see your Github activity history for a year.
Yuuma
yuuma at 2021年12月20日 10:00:00
- 2021年12月17日
- 技術情報
Javascriptを使用して、Excelのセルにファイルアップロードを挿入する方法
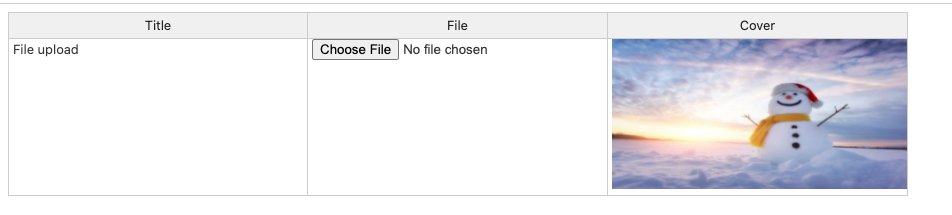
今回は、Handsontableを使って、ファイルアップロードボタンを挿入する方法と、セル内に画像を表示する方法を紹介したいと思います。
Handsontableは、デフォルトで11個のエイリアスを提供することができます。
- time
- text
- select
- password
- numeric
- handsontable
- dropdown
- date
- checkbox
- base
- autocomplete
しかし、file editorでは、これまで提供できませんでした。ファイルアップロードボタンをセルに挿入することは、自分自身で発見しました。4つの方法があるのですが、今日はそのうちの1つ、cells内で呼び出されるrenderer関数を使った方法を紹介します。
今回は、rendererの呼び出し方と、ファイルアップロードボタンと画像の表示方法を中心に説明します。
まず、htmlファイルを作成し、必要なスクリプトファイルを挿入します。
<div id="example1" class="hot "></div>
<script src="https://cdn.jsdelivr.net/npm/handsontable@11.0/dist/handsontable.full.min.js"></script>
<link type="text/css" rel="stylesheet" href="https://cdn.jsdelivr.net/npm/handsontable@11.0/dist/handsontable.full.min.css" />
次に、Handontableを作成し、cells内にrendererを呼び出すための条件をいくつか作成します。commentsとcoversにcustom renderer関数を呼び出すことにします。
const hot = new Handsontable(container, {
data,
colWidths: [100, 100, 200],
colHeaders: ['Title', 'File', 'Cover'],
colWidths: 300,
renderer: 'html',
height: 200,
columns: [
{ data: 'title' },
{ data: 'comments', renderer: safeHtmlRenderer },
{ data: 'cover', renderer: coverRenderer }
],
cells: function (row, col, prop) {
var cellProperties = {};
if(col === 1){
cellProperties.renderer = safeHtmlRenderer
}
if(col === 2){
cellProperties.renderer = coverRenderer
}
},
licenseKey: 'non-commercial-and-evaluation'
});renderer関数の内部では、カスタムhtmlのデザインを作成し、innerHTMLプロパティでtdに挿入することができます。
function safeHtmlRenderer(instance, td, row, col, prop, value, cellProperties) {
Handsontable.renderers.TextRenderer.apply(this, arguments);
td.innerHTML = '<div><input type="file" id="filechange" name="file[]" class="filebutton"></div>';
return td;
}また、rendererで画像を表示することもできます。
function coverRenderer(instance, td, row, col, prop, value, cellProperties) {
Handsontable.renderers.TextRenderer.apply(this, arguments);
td.innerHTML = '<img src="imges/winter.jpg" width="300" height="150" >';
return td;
}ここまでお読みいただき、ありがとうございました。
By Ami
asahi at 2021年12月17日 10:00:00
- 2021年12月16日
- Web Service
Tips & best practices for Laravel 8
This article will show you the mysterious tricks that might help you when writing code with Laravel.
1.Use local scopes when you need to query things
Laravel has a nice way to write queries for your database driver using Query Builder. Something like this:
$orders = Order::where(‘status’, ‘delivered’)->where(‘paid’, true)->get();
This is pretty nice.But this bit of code can be better written if we use local scopes.
Local scopes allow us to create our Query Builder methods we can chain when we try to retrieve data. For example, instead of ->where() statements, we can use ->delivered() and ->paid() in a cleaner way.
First, in our Order model, we should add some methods:
class Order extends Model
{
...
public function scopeDelivered($query) {
return $query->where('status', 'delivered');
} public function scopePaid($query) {
return $query->where('paid', true);
}
}
When declaring local scopes, you should use the scope[Something] exact naming. In this way, Laravel will know that this is a scope and will make use of it in your Query Builder. Make sure you include the first argument that is automatically injected by Laravel and is the query builder instance.
$orders = Order::delivered()->paid()->get();
For more dynamic retrieval, you can use dynamic local scopes. Each scope allows you to give parameters.
class Order extends Model
{
...
public function scopeStatus($query, string $status) {
return $query->where('status', $status);
}
}$orders = Order::status('delivered')->paid()->get();
Laravel uses by default where[Something] to replace the previous scope. So instead of the previous one, you can do:
Order::whereStatus(‘delivered’)->paid()->get();
Laravel will search for the snake_case version of Something from where[Something]. If you have status in your DB, you will use the previous example. If you have shipping_status, you can use:
Order::whereShippingStatus(‘delivered’)->paid()->get();
2.Magic scopes
When building things, you can use the magic scopes that are already embedded
- Retrieve the results by
created_at, descending:
User::latest()->get();
- Retrieve the results by any field, descending:
User::latest('last_login_at')->get();
- Retrieve results in random order:
User::inRandomOrder()->get();
- Run a query method only if something’s true:
3.Do not store model-related static data in configs
Instead of this:
BettingOdds.php
class BettingOdds extends Model
{
...
}
config/bettingOdds.php
return [
'sports' => [
'soccer' => 'sport:1',
'tennis' => 'sport:2',
'basketball' => 'sport:3',
...
],
];
And accessing them using:
config(’bettingOdds.sports.soccer’);
I prefer doing this:
BettingOdds.php
class BettingOdds extends Model
{
protected static $sports = [
'soccer' => 'sport:1',
'tennis' => 'sport:2',
'basketball' => 'sport:3',
...
];
}
And access them using:
BettingOdds::$sports['soccer'];
Because it’s easier to be used in further operations:
class BettingOdds extends Model
{
protected static $sports = [
'soccer' => 'sport:1',
'tennis' => 'sport:2',
'basketball' => 'sport:3',
...
];public function scopeSport($query, string $sport)
{
if (! isset(self::$sports[$sport])) {
return $query;
}
return $query->where('sport_id', self::$sports[$sport]);
}
}
Now we can enjoy scopes:
BettingOdds::sport('soccer')->get();
4.Use collections instead of raw-array processing
Back in the days, we were used to working with arrays in a raw way:
$fruits = ['apple', 'pear', 'banana', 'strawberry'];foreach ($fruits as $fruit) {
echo 'I have '. $fruit;
}
Now, we can use advanced methods that will help us process the data within arrays. We can filter, transform, iterate and modify data inside an array:
$fruits = collect($fruits);$fruits = $fruits->reject(function ($fruit) {
return $fruit === 'apple';
})->toArray();['pear', 'banana', 'strawberry']
Tsuki
tsuki at 2021年12月16日 10:00:00
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ