技術情報
- 2021年12月06日
- 技術情報
PHP 8.1 is here
The PHP team has released PHP 8.1. Let’s see a bit of some main features they have added.
Improvements
There are many improvements as follow.
- Enumerations
- Readonly properties
- Pure Intersection Types
- never return type
- First-class Callable Syntax
- New array_is_list function
- and many more
We will walk through some feature more details.
Enumerations
PHP 8.1 supports Enumerations (Enums) natively, providing an API for defining and working with Enums:
enum Data
{
case Draft;
case Published;
case Archived;
}
function acceptStatus(Data $data) {...}Read-only Properties
Read-only properties cannot be changed after they are initialized. You can be confident that your data classes are consistent. PHP 8.1 can reduce boilerplate by defining public properties the author does not intend to change.
class Sample
{
public readonly Data $data;
public function __construct(Data $data)
{
$this->data = $data;
}
}First-class Callable Syntax
You can make make a closure from a callable by calling it and passing "...“
function sum(int $a, int $b) {
// ...
}
$sum = sum(...);
$sum(1, 5);
$sum(5, 3);and there are still more interesting features to look more detail. Please check the official documentation for more detail.
Yuuma
yuuma at 2021年12月06日 10:00:00
- 2021年12月03日
- 技術情報
JS(Chart.js)-内側と外側にdata labelsを表示する方法
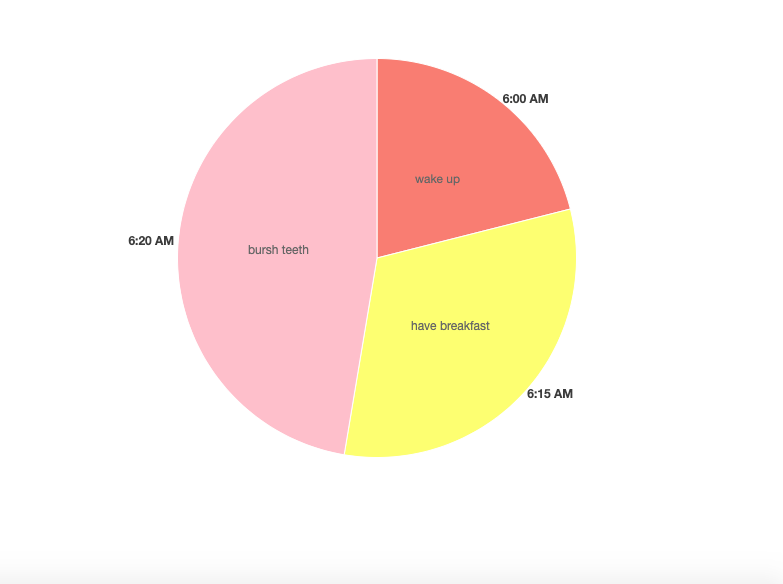
今回は、Chart.js DataLabelsを使って、canvasに円グラフを描く方法をご紹介します。
まずは、htmlファイルを作成し、その中に4つのスクリプトファイルをインポートしています。
<script src="https://cdn.jsdelivr.net/npm/chart.js@3.0.0/dist/chart.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js@2.8.0"></script>
<script src="https://cdn.jsdelivr.net/npm/chartjs-plugin-datalabels@2.0.0"></script>
<script src="https://unpkg.com/chart.js-plugin-labels-dv@3.0.5/dist/chartjs-plugin-labels.min.js"></script><canvas id="my-chart"></canvas>以上のcanvasにに円グラフを作成します。円グラフを作成するには、このようなdataが含まれている必要があります。
var data = {
labels: ["6:00 AM", "6:15 AM", "6:20 AM"],
datasets: [
{
labels: ["wake up", "have breakfast", "bursh teeth"],
backgroundColor: ["#FA8072","#FFFF66","#FFC0CB"],
data: [40, 60, 90],
borderWidth: 1,
}
]
};また、typeをpieにする必要もあります。もう一つ、datalabelsを表示するために、グラフにプラグイン名をインポートします。
var myChart = new Chart(ctx, {
type: 'pie',
data: data,
plugins: [ChartDataLabels],
});ラベルを外に見せるために、このようなセットを挿入します。
labels: {
render: function(d) {
return `${d.label}`;
},
position: 'outside',
},円グラフの中で、ラベルを表示するには次のようにします。
datalabels: {
formatter: function(value, context) {
return context.dataset.labels[context.dataIndex];
},
},その結果が上部に表示されています。
この記事を楽しんでもらえたら嬉しいです。
By Ami
asahi at 2021年12月03日 10:00:00
- 2021年12月02日
- 技術情報
Laravel フォーム入力内容の復元
入力フォームを設置する場合に編集モードでは、DBに登録されている値を初期値として表示、
またバリデーションエラーになった場合はフォームに入力した値を復元したい場合があります。
そのような場合は、Laravelではold関数を使用することで簡単に対応できますので
その方法をシェアしたいと思います。
old関数について
{{ old(‘name’) }}
old関数の第2引数にデフォルト値が設定できます。DBに登録されている値を
初期値として表示したい場合に便利です。
{{ old(‘name’, ‘デフォルト値’) }}
テキストボックスの使用例
最もシンプルなテキストボックスでの使用例です。
<input type="text" name="name" id="name" value="{{ old('name', $recdata['name']) }}">
ラジオボタンの使用例
ラジオボタンは複数の選択肢の中からひとつだけ選択できる入力フォーマットです。
選択しているボタンの属性に「checked」をつけ加えるためold関数の値から条件分岐を設定しています。
@foreach ($list as $item)
<span><input type="radio" name="gender" id="gender{{$item->code}}" value="{{$item->code}}"
{{ old('gender', $recdata['gender'])==$item->code ? 'checked':'' }}>
<label for="gender{{$item->code}}" class="radio">{{$item->value}}</label></span>
@endforeach
プルダウンメニューの使用例
プルダウンメニューは複数の選択肢の中からひとつだけ選択できる入力フォーマットです。
選択しているリストアイテムの属性に「selected」をつけ加えるためold関数の値から条件分岐を設定しています。
<select name="pref" id="pref">
<option value="">都道府県を選択</option>
@foreach ($prefs as $pref)
<option value="{{$pref->code}}"
{{ old('pref', $recdata['pref'])==$pref->code ? 'selected':'' }}>
{{$pref->value}}</option>
@endforeach
</select>
チェックボックスの使用例
チェックボックスは複数の選択肢の中から複数選択可能な入力フォーマットです。
複数選択可能なため配列になっています。
選択しているチェックボックスの属性に「checked」をつけ加えるためold関数の値から条件分岐を設定しています。
@foreach ($list as $item)
<span><input type="checkbox" name="fav_player[]" id="fav_player{{$item->code}}" value="{{$item->code}}"
@if (is_array(old("fav_player", $recdata['fav_player'])) && in_array($item->code, old('fav_player', $recdata['fav_player']))) checked @endif>
<label for="fav_player{{$item->code}}" class="checkbox">{{$item->value}}</label></span>
@endforeach
木曜日担当:nishida
nishida at 2021年12月02日 10:00:00
- 2021年11月29日
- 技術情報
Deleting .env file back from Git
Sometimes , we accidentally pushed a file with some username , password or secret tokens etc. It has a variety security concerns for your project and this should be removed back from Git.
Git ignore
First thing you need to do is to add the file you don’t want to push to git at .gitignore file. Add it in .gitignore , commit and push it.
# Secret file
.envBut this will not change any effects to .env as the file is already pushed before and .gitignore doesn’t untracked the already committed changes
Deleting the file
So we have to remove the specific file , .env in our case from the git remote repo entirely. We can use the following command.
git rm -r --cached .envIf we push the changes , the .env file will be remove from the remote repository
Git History
However, one more thing is left which is git histories. We can check the .env file contents also in git histories. So we need to remove the specific git history as well to hide the .env contents.
To remove the file altogether, we can use like following.
git filter-branch --index-filter "git rm -rf --cached --ignore-unmatch .env" HEADWhen you push this time, you have to use –force option.
git push --forceIf we look at our history, we can still see the commits that include .env file but the content is empty.
That’s all for now.
Yuuma
yuuma at 2021年11月29日 10:00:00
- 2021年11月26日
- 技術情報
JavaScript HandSonTable Renderer Memo

I would like to share about how to renderer as your desire cells when you use HandSonTable. HandSonTable can’t directly insert html elements into cells. But after declaration renderer:html in our table of cell, we can use html elements as your desire. Second ways is to create custom renderer in cells properties with our own way.
Firstly we will create simple html file. In this file we will import handsontable.min.js and handsontable.min.css. We can get these file script from this site cdnjs.com.
<script src="https://cdn.jsdelivr.net/npm/handsontable@11.0/dist/handsontable.full.min.js"></script>
<link type="text/css" rel="stylesheet" href="https://cdn.jsdelivr.net/npm/handsontable@11.0/dist/handsontable.full.min.css" />To insert our table, create a div with id attribute and call this id with JS querySelector.
<div id="example1" class="hot "></div>
const container = document.querySelector('#example1');Usage of HandSonTable
const hot = new Handsontable(container, {
data : data
});const data = [
{ id: 1, name: 'Suga', isActive: true, date: '2021-11-25' },
{ id: 2, name: 'Jimin', isActive: false, date: null },
{ id: 3, name: 'JHope', isActive: true, date: null },
{ id: 4, name: 'V', isActive: false, date: null },
];If you want to add colsHeader, set to true => colHeaders : true
And if you want to add strict cell type and render columns, we can set inside columns.
columns: [
{ data: 'id', type: 'text' },
// 'text' is default, you don't actually need to declare it
{ data: 'name', renderer: yellowRenderer },
// use default 'text' cell type but overwrite its renderer with yellowRenderer
{ data: 'isActive', type: 'checkbox' },
{ data: 'date', type: 'date', dateFormat: 'YYYY-MM-DD' },
],I will add another custom renderer named with greenRenderer but this greenRenderer will not add all the cell, just add some row. So I will use this greenRenderer inside a cell.
cells(row, col, prop) {
if (row === 3 && col === 0) {
this.renderer = greenRenderer;
}
}yellowRenderer function => this function will add all the cell with background color yellow.
const yellowRenderer = function(instance, td, row, col, prop, value, cellProperties) {
Handsontable.renderers.TextRenderer.apply(this, arguments);
td.style.backgroundColor = 'organe';
};greenRenderer function => this function will add some of cell with background color red.
const greenRenderer = function(instance, td, row, col, prop, value, cellProperties) {
Handsontable.renderers.TextRenderer.apply(this, arguments);
td.style.backgroundColor = 'purple';
};
If you want to set custom colWidths , then set colWidths to your desire value.
colWidths : 100Hope you enjoyed about this article!
By Ami
asahi at 2021年11月26日 10:00:00
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ