アプリ関連ニュース
- 2023年12月11日
- AI
Google releases Gemini
Google’s generative AI chatbot, Bard, is set to receive a substantial upgrade with the integration of Gemini, Google’s latest and most advanced AI model. This update is expected to significantly enhance Bard’s capabilities, providing it with improved reasoning, planning, and understanding, among other features. Gemini, available in Ultra, Pro, and Nano sizes, is designed to run seamlessly across a range of devices, from mobile phones to data centers.
The deployment of Gemini to Bard will occur in two phases. Initially, Bard will be upgraded with a tailored version of Gemini Pro, available in English in over 170 countries. Subsequently, Google plans to introduce Bard Advanced, granting users access to Gemini Ultra, the most powerful AI model. These enhancements mark the most significant quality improvement for Bard since its initial launch, promising heightened proficiency in tasks such as understanding and summarizing content, reasoning, brainstorming, writing, and planning.

Gemini Pro underwent rigorous testing against industry-standard benchmarks, showcasing its superiority over GPT-3.5 in six out of eight tests, including MMLU and GSM8K. However, it’s worth noting that GPT-3.5 is over a year old, framing this launch as more of a catch-up move than a revolutionary leap. Despite this, the improvements aim to position Bard as a more capable and versatile AI, offering users an enhanced and refined experience.
Gemini Pro will initially power text-based prompts in Bard, with plans for future expansion to include multimodal support, incorporating both text and images. Looking ahead to 2024, Bard Advanced will make its debut, featuring Gemini Ultra. This version promises a comprehensive AI experience capable of understanding and acting on various types of information, such as text, images, audio, video, and code. Google intends to initiate a trusted tester program for Bard Advanced before a broader release, emphasizing the importance of safety checks in the development process. The update builds upon several recent improvements to Bard, positioning it as a robust and evolving AI chatbot.
yuuma at 2023年12月11日 10:00:00
次世代MRデバイスMeta Quest 3とApple Vision Proの比較について
VRデバイスだったMeta Quest 2がカラーパススルーによるAR機能を追加してMeta Quest 3にアップデートされ、また来年度にはApple社より注目されているMRデバイス Apple Vision Proが発売予定とされています。

Image credit: Apple
Meta Quest 3が499ドル(約7.5万円)という比較的安価で発売されているのに対して、Apple Vision Proの販売価格は3,499ドル(約52万円)と高価です。
MRデバイスとして注目されているこれらの2機種ですが、先日、中国のWellsenn XR社より製造原価の推計が発表されました。
(参考記事) Meta Quest 3 & Apple Vision Pro Production Costs Estimated By Supply Chain Analyst Firm
https://www.uploadvr.com/meta-quest-3-apple-vision-pro-production-cost-estimate/
(参考記事) Apple「Vision Pro」の製造原価は「Meta Quest 3」の4倍以上か——中国アナリストが推計
https://www.moguravr.com/manufacturing-costs-for-apple-vision-pro-and-meta-quest-3/
この記事によれば、Meta Quest 3の原価は430ドルに対して、Apple Vision Proの原価は1,726ドルになります。
Meta Quest 3の原価は430ドルで販売価格は499ドルなのでMeta社はMeta Quest 3を販売することで利益はほぼないか、損失している可能性もあるとのことです。Meta社は利益よりもVR/MRの普及とマーケットのシェア獲得に注力しているようです。
Meta Quest 3ではハイエンドのMR/VR用チップセット「Snapdragon XR2 Gen 2」が採用されており、これが最も原価がかかっているパーツとされています。
一方、Apple社は高性能の独自チップセットM2やR1が搭載される予定ですが、Apple Vision Proで最も原価がかかっているパーツはディスプレイで、高価なソニー社マイクロOLEDディスプレイが採用予定で、おそらく画面の綺麗さ、MR合成の自然さはMeta Quest 3以上と推測されます。
現状のMeta Quest 3で高クオリティのMR体験が可能なので、それよりも高品質なApple Vision ProのMRには期待は高まります。
木曜日担当:nishida
nishida at 2023年11月30日 10:00:00
- 2023年11月29日
- AI
ローカルでチャットAIを動作させる
tanaka at 2023年11月29日 10:00:00
- 2023年11月28日
- 技術情報
Writing User CRUD API Feature Test in Laravel
Laravel empowers developers to build efficient and robust APIs effortlessly. Feature testing is an indispensable aspect of ensuring the reliability and functionality of our APIs, especially when it involves user CRUD operations. In this blog post, we’ll take a step-by-step journey through the code to feature test a User CRUD API in Laravel.
Step 1: Setting Up the Test Environment
Create a test class file with the following command.
php artisan make:test UserCrudApiTestThe test class file created can be found at tests/Feature/UserCrudApiTest.php and codes are as follows.
<?php
namespace Tests\Feature;
use Illuminate\Foundation\Testing\RefreshDatabase;
use Illuminate\Foundation\Testing\WithFaker;
use Tests\TestCase;
class UserCrudApiTest extends TestCase
{
/**
* A basic feature test example.
*
* @return void
*/
public function test_example()
{
$response = $this->get('/');
$response->assertStatus(200);
}
}Step 2: Define and modify the Test Class
Import necessary classes and traits. And remove default test_example method.
<?php
namespace Tests\Feature;
use Illuminate\Foundation\Testing\RefreshDatabase;
use Illuminate\Foundation\Testing\WithFaker;
use Tests\TestCase;
use App\Models\User;
class UserCrudApiTest extends TestCase
{
use RefreshDatabase;
}The `UserCrudApiTest` class is declared, extending `TestCase` and using `RefreshDatabase` for database isolation.
`RefreshDatabase` ensures a clean database state for each test, and `TestCase` is the base test case class. `User` is imported to create and interact with user models.
Step 3: Testing User Creation
public function test_user_can_be_created()
{
$userData = [
'name' => 'John Doe',
'email' => 'john@example.com',
'password' => bcrypt('password123'),
];
$response = $this->json('POST', '/api/users', $userData);
$response->assertStatus(201)
->assertJson([
'name' => 'John Doe',
'email' => 'john@example.com',
]);
$this->assertDatabaseHas('users', [
'name' => 'John Doe',
'email' => 'john@example.com',
]);
}This method tests the creation of a user. The `$this->json(‘POST’, ‘/api/users’, $userData)` line sends a POST request to create a user with the specified data. Assertions ensure a successful response, correct JSON structure, and that the user is stored in the database.
Step 4: Testing User Retrieval
public function test_user_can_be_retrieved()
{
$user = factory(User::class)->create();
$response = $this->json('GET', "/api/users/{$user->id}");
$response->assertStatus(200)
->assertJson([
'name' => $user->name,
'email' => $user->email,
]);
}This method tests the retrieval of a user. A user is created using the factory, and a GET request is made to fetch the user’s details. Assertions verify a successful response and the correctness of the returned data.
Step 5: Testing User Update
public function test_user_can_be_updated()
{
$user = factory(User::class)->create();
$updateData = [
'name' => 'Updated Name',
'email' => 'updated.email@example.com',
];
$response = $this->json('PUT', "/api/users/{$user->id}", $updateData);
$response->assertStatus(200)
->assertJson($updateData);
$this->assertDatabaseHas('users', [
'id' => $user->id,
'name' => 'Updated Name',
'email' => 'updated.email@example.com',
]);
}This method tests updating a user’s details. A user is created, and a PUT request updates the user’s data. Assertions check for a successful response, the correctness of the returned JSON, and the updated data in the database.
Step 6: Testing User Deletion
public function test_user_can_be_deleted()
{
$user = factory(User::class)->create();
$response = $this->json('DELETE', "/api/users/{$user->id}");
$response->assertStatus(204);
$this->assertDatabaseMissing('users', ['id' => $user->id]);
}This method tests the deletion of a user. A user is created, and a DELETE request is made to delete the user. Assertions ensure a successful response and confirm that the user is no longer present in the database.
After writing the necessary test methods, we can test with the following artisan command.
php artisan test --filter UserCrudApiTestThis command uses the --filter option to specify a particular test class, in this case, UserCrudApiTest. Only the tests within the UserCrudApiTest class will be executed.
The --filter option can also be used to run specific methods within a test class. For example:
php artisan test --filter UserCrudApiTest::test_user_can_be_createdAlso php artisan test can be used to run all the tests in the application (all test files under tests dir).
Conclusion
Feature testing User CRUD operations in a Laravel API provides confidence in the functionality and reliability of the endpoints. Each step, from setup to testing each CRUD operation, contributes to a robust testing suite that helps maintain a high standard of code quality in our Laravel applications.
Hope you enjoy that.
Asahi
waithaw at 2023年11月28日 10:00:00
- 2023年11月27日
- AI
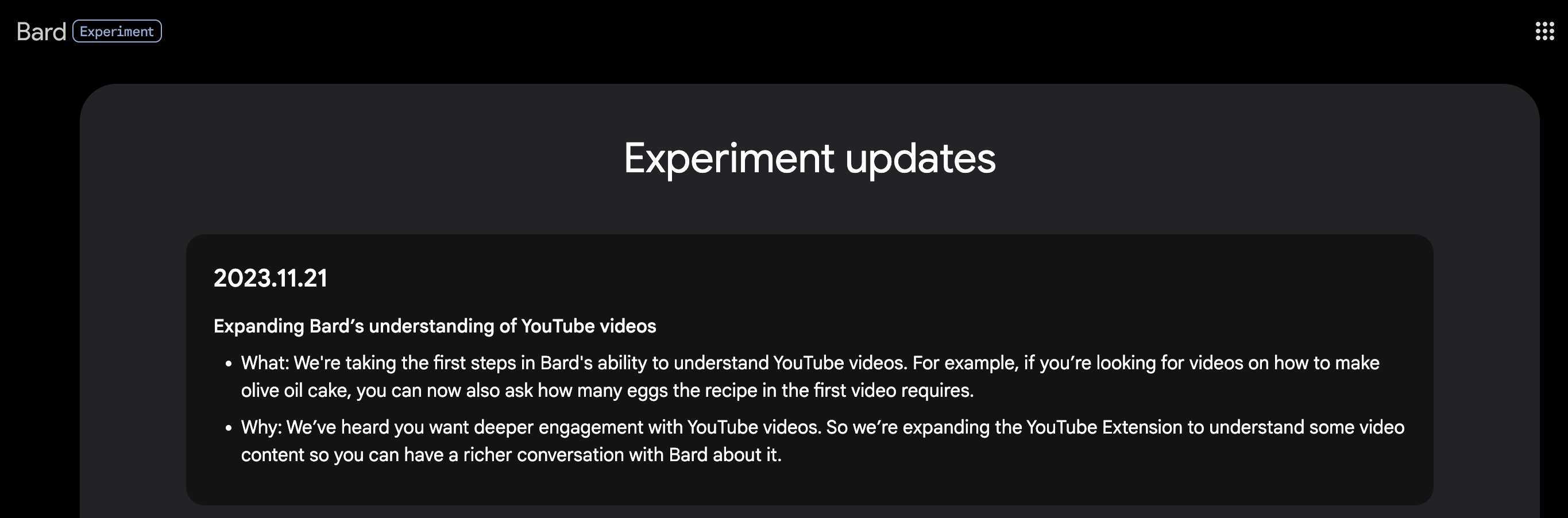
Google Bard expands capabilities to answer queries about YouTube videos
Google has recently announced a significant enhancement to its Bard AI chatbot, enabling it to provide specific answers to questions related to YouTube videos. While the initial YouTube Extension for Bard, launched in September, allowed users to find specific videos, the latest update empowers the chatbot to respond to queries about the content within videos.
This advancement means users can now engage in richer conversations with Bard, asking detailed questions such as the number of eggs required in a recipe featured in a particular video. Google acknowledges the users’ desire for deeper interaction with YouTube content and aims to fulfill this through Bard’s expanded capabilities.
This development follows YouTube’s recent experimentation with new generative AI features, introducing an AI conversational tool that answers questions about the platform’s content. This tool employs large language models to generate responses, utilizing information from both YouTube and the broader web. Users can now pose questions about the video they are watching, and the AI-driven conversation unfolds in real-time alongside the video playback. Additionally, YouTube has introduced a comments summarizer tool, leveraging generative AI to organize and summarize topics discussed in video comments, providing users with an overview of community discussions.
Coinciding with these updates, Google has expanded access to Bard for teenagers in most countries globally. In a blog post, Google highlighted the potential for teens to use Bard as a tool for inspiration, discovering new hobbies, and solving everyday problems. Whether seeking advice on university applications or exploring leisure activities, teens can now tap into Bard’s capabilities for a wide range of inquiries. This move aligns with Google’s commitment to making Bard a valuable resource for teens across various aspects of their lives.
Yuuma
yuuma at 2023年11月27日 10:00:00
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ