MySQL 照合順序設定による検索結果の違い(2)
- 2021年5月27日
- 技術情報
今回はデータベースを作成する際の照合順序設定によってどのように検索結果に影響を与えるかをシェアしたいと思います。
本記事は前回の「MySQL 照合順序設定による検索結果の違い(1)」の続きとなります。
前回の記事で作成したそれぞれのテーブルにて以下のSELECT文で名前に「nishi」が含まれているレコードを検索しました。
SELECT * FROM `test` WHERE name LIKE '%nishi%';
検索結果は以下の通りです。
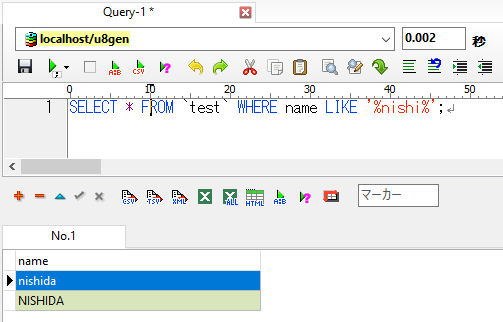
u8genの場合:
u8uniの場合:
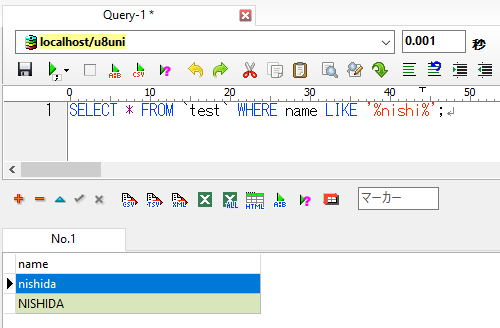
u8genの場合もu8uniの場合も検索結果は全く同じでした。
小文字の「nishi」で検索をおこなっても、大文字「NISHI」のレコードも抽出できました。
以下のSELECT文の場合はどうでしょうか。
名前に「ニシ」(半角カナ)が含まれているレコードの検索をおこないました。
SELECT * FROM `test` WHERE name LIKE '%ニシ%';
検索結果は以下の通りです。
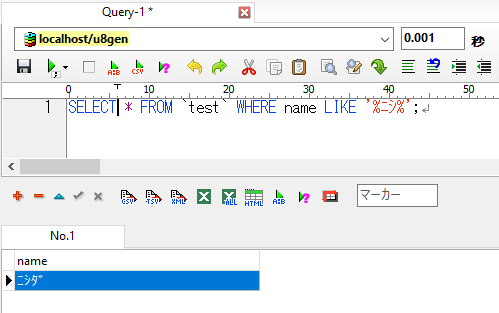
u8genの場合:
u8uniの場合:
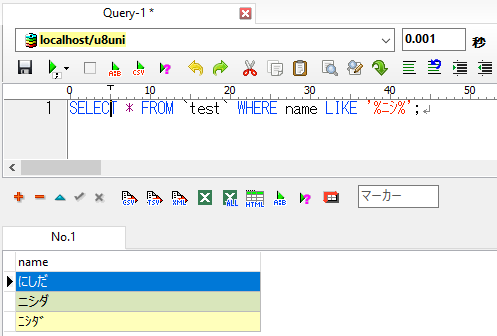
検索結果に違いがでました。
u8genでは名前に「ニシ」(半角カナ)が含まれているレコードのみが抽出されているのに対して、u8uniでは「にし」(ひらがな)や「ニシ」(全角カナ)のレコードも抽出されました。
このような違いをふまえて照合順序の設定をおこなう必要があります。
しかし、例えば「utf8_general_ci」で照合順序が設定されているデータベースを用いたプロジェクトで、検索フォームで入力された文字の「全角・半角」は区別しないで検索したい場合、どのようにすればいいのでしょうか。
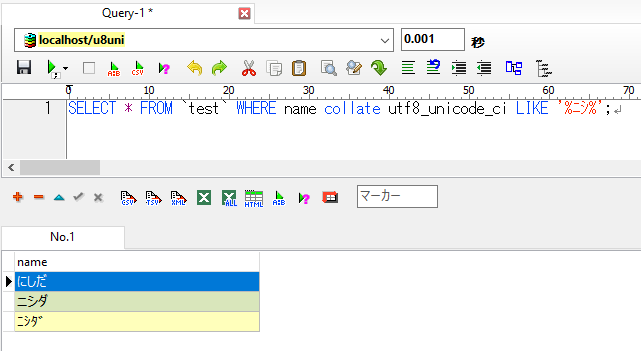
その場合は、SELECT文を以下のように修正することで「utf8_general_ci」で照合順序が設定されているデータベースにおいても、「全角・半角」の区別なく、レコードを抽出することが可能になります。
SELECT * FROM `test` WHERE name collate utf8_unicode_ci LIKE '%ニシ%';
検索結果
木曜日担当:nishida
nishida at 2021年05月27日 10:00:47
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ