アプリ関連ニュース
- 2022年4月15日
- 技術情報
知っておいていただきたいこと – 2
今回も、Laravelの知っておいた方がいいとおもったことをいくつか紹介します。
Tip – 1 #Laravel #Eloquent Tip :
これはLaravelのv9.8.*で利用可能です。
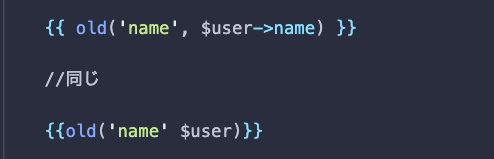
Eloquentモデル全体を旧関数の第2引数として渡すことができます。
古い関数に提供された最初の引数は、Eloquent属性の名前であると仮定します。
Tip – 2 #squish グローバルヘルパーメソッド
これは、単語間を含む文字列からすべての余分な空白を削除します。steroidsの「trim」みたいなものです。

ということで、今回はこれで終わります。
金曜担当 – Ami
asahi at 2022年04月15日 10:00:00
- 2022年4月14日
- Web Service
ウェブデザイナーのためのインスピレーションを与えるベストサイト
CSS Design Awards
このサイトは、クリエイティビティ、機能性、ユーザビリティのバランスを特に重視したデザイナーやウェブエージェンシーを表彰するサイトです。
Designspiration
このサイトには、ウェブデザイナーのための素晴らしいデザインがたくさんあります。
Dribbble
Dribbble には、ウェブデザインのほか、アニメーション、ブランディング、イラスト、モバイル、印刷、プロダクトデザイン、タイポグラフィのカテゴリがあります。
Pinterestでは、Webデザインだけでなく、さまざまな種類のデザインを提供しています。
インスタグラムは、あらゆる種類のビジュアルコンテンツを10億人のアクティブユーザーに届けることができるNo.1プラットフォームとなりました。
Codepen
HTML、CSS、JavaScriptのコードエディターで必需品です。”ブラウザにコードを入れる”
CSS NECTAR
CSSnectarでは、トリプルベットされたインスピレーション溢れるウェブサイトを紹介しています。 訪問者は、国、特徴、カテゴリー、カラータグなどのフィルターやタグを使って、サイトを見て回ることができます。
Niice
優れたデザインコンセプトのアイデアを提供するサイトです。
By Tsuki
tsuki at 2022年04月14日 10:00:00
- 2022年4月14日
- 技術情報
DataTablesを使用したテーブル生成とサーバーサイド連携(8)
本記事ではDataTablesを使用したテーブル生成方法とサーバーサイド連携方法をシェアします。
前回の記事でページングおよびソート処理の実装が完了しましたので
今回は検索(フィルタリング)処理の作成をおこなっていきたいと思います。
nishida at 2022年04月14日 10:00:00
- 2022年4月12日
- 技術情報
6 Tips for optimizing a laravel application
Today, I would like to share about some tips for optimizing a laravel application. Let’s take a look.
1. Cache routes, config and views
Caching speeds up your application. This is important when deploying a application to a production environment.
To cache your routes, you can use the following command:
php artisan route:cache
To clear the route cache, you can use the following command:
php artisan route:clear
To cache config, you can use the following command:
php artisan config:cache
To cache your views, you can use the following command:
php artisan view:cache
2. Remove unused services
You should remove unused services when the application grows. This can be done by removing the service from the config/app.php file.
3. Remove unused packages
To keep the app clean, you should remove unused packages from the application. This can be done by removing the package from the composer.json file or by running the following command:
composer remove package-name
4. Remove development dependencies
You should also remove development dependencies when deploying to production. This can be done by running the following command:
composer install –prefer-dist –no-dev -o
5. Composer Autoload Optimization
For your applications, you should use the composer autoload optimization feature as the autoloader can take significant time for each request:
composer dumpautoload -o
The -o flag will convert PSR-0/4 autoloading to classmap to become a faster autoloader.
6. Precompile your assets
If npm is used for your front-end development, you should precompile your assets. This can be done by running the following command:
npm run production
This will compile the assets and create public/assets directory.
This is all for now. Hope you enjoy that.
By Asahi
waithaw at 2022年04月12日 10:00:00
- 2022年4月11日
- Apple
WWDC22
This year, the Apple Worldwide Developers Conference (WWDC) will be an online-only event, June 6-10. However, Apple said it hosted a face-to-face session at Apple Park on June 6, with some developers and students watching the State of the Union address and video together with the online community.

WWDC is traditionally a software-focused event where Apple details its upcoming updates to iOS, iPadOS, macOS, tvOS, and watchOS. Last year, for example, Apple announced a series of software enhancements such as SharePlay support for FaceTime, the ability to store IDs digitally in Apple Wallet, widget support for iPadOS, and new privacy features with its subscription service, iCloudPlus.
But that doesn’t mean WWDC is always about software. Past events have seen the launch of the new Mac Pro and HomePod, as well as the updated iMac and iPad Pro. At Apple’s 2021 conference, it announced that it would be moving its Mac lineup to its own Arm-based Apple Silicon.
You can check out the more detail of the program here if you are interested.
Yuuma
yuuma at 2022年04月11日 01:55:31
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ