技術情報
- 2023年10月17日
- 技術情報
Microsoft Phasing Out NTLM in Favor of Kerberos for Enhanced Authentication and Security in Windows 11
Microsoft has revealed its plan to phase out NT LAN Manager (NTLM) authentication in Windows 11 to enhance security and focus on bolstering the Kerberos authentication protocol. This move includes the introduction of features like Initial and Pass Through Authentication Using Kerberos (IAKerb) and a local Key Distribution Center (KDC) for Kerberos in Windows 11.

NTLM, a security protocol from the 1990s, was originally designed for user authentication, integrity, and confidentiality. However, it has been replaced by Kerberos since Windows 2000, though it continues to be used as a fallback option. NTLM relies on a three-way handshake for user authentication and uses password hashing, while Kerberos employs a two-part process with encryption.
NTLM has been found to have inherent security weaknesses and is vulnerable to relay attacks, which could potentially allow unauthorized access to network resources.
Microsoft is actively working to address hard-coded NTLM instances in its components as part of its preparation to disable NTLM in Windows 11. These changes will be enabled by default, with no need for additional configuration in most scenarios. NTLM will still be available as a fallback for maintaining compatibility with existing systems.
Asahi
waithaw at 2023年10月17日 10:00:00
Free Alternatives to GPT-4
Today, I would like to share about 3 free alternatives to GPT-4. Let’s take a look.
LlaMA 2
LlaMA 2 is a cutting-edge open-source large language model developed by Meta AI. It’s available for commercial use and comes with pre-trained models, fine-tuned models, and code resources. You can find all these assets on HuggingFace. You can also get a feel for how well the model performs by trying it out on HuggingChat. By making LlaMA 2 openly accessible, Meta AI is empowering researchers and developers to create innovative applications that leverage advanced language capabilities.
PaLM 2
Google AI’s PaLM 2 is Google’s latest large language model, excelling in advanced reasoning tasks like coding, mathematics, classification, question answering, translation, multilingual proficiency, and natural language generation. It surpasses previous state-of-the-art large language models like the original PaLM due to its optimized compute-scaling approach, improved dataset mixture, and architectural enhancements. You can access PaLM 2 for free using Bard. While there’s still room for improvement compared to GPT-4 in terms of quality and performance, it offers impressive capabilities.
Claude 2
Claude 2 represents the latest version of Anthropic’s conversational AI assistant. It offers improved performance, longer responses, and can be accessed through an API as well as a new public beta website, claude.ai. Developers at Anthropic have focused on enhancing its capabilities in areas such as coding, mathematics, and logical reasoning compared to earlier Claude versions. For instance, Claude 2 recently achieved a score of 76.5% on the multiple-choice section of the Bar exam, a significant improvement from Claude 1.3’s 73.0%. You can access various Claude models on Poe and experience their performance firsthand.
Conclusion
Despite GPT-4 being unavailable to the public, there are other promising open-source large language models emerging as alternatives that are accessible to everyone. While these models may not be as massive as GPT-4, they show that cutting-edge language AI is evolving rapidly and becoming more widely available. These freely accessible models excel in fields such as mathematics, coding, and logical reasoning, making them suitable replacements for various applications.
Asahi
waithaw at 2023年10月03日 10:00:00
Microsoft has recently unveiled its AI companion
Copilot will start rolling out on Windows 11 starting September 26 through a free Windows 11 update.
Microsoft Copilot, the AI companion from Microsoft, is designed to seamlessly integrate with all Microsoft applications and experiences, encompassing Microsoft 365, Windows 11, Edge, and Bing. This means that users will have the ability to harness AI support across a wide spectrum of tasks within their workflows across these diverse Microsoft applications.

The pricing for Microsoft Copilot is contingent upon the specific application it is integrated with. Beginning November 1, enterprise customers can access Microsoft 365 Copilot for a substantial cost of $30 per user per month.
However, for the other applications, Microsoft has announced that Copilot will be introduced in its initial version as part of a complimentary update to Windows 11, commencing on September 26. It will also be progressively integrated across Bing, Edge, and Microsoft 365 Copilot throughout the fall.
Bing is also set to incorporate support for OpenAI’s latest DALL.E 3 model, enhancing its ability to provide personalized search results that take into account your search history. Additionally, Bing is introducing an AI-powered shopping feature for a more tailored shopping experience. Moreover, Bing Chat Enterprise is receiving updates aimed at enhancing its mobile usability and visual appeal.
Asahi
waithaw at 2023年09月26日 10:00:00
- 2023年09月12日
- 技術情報
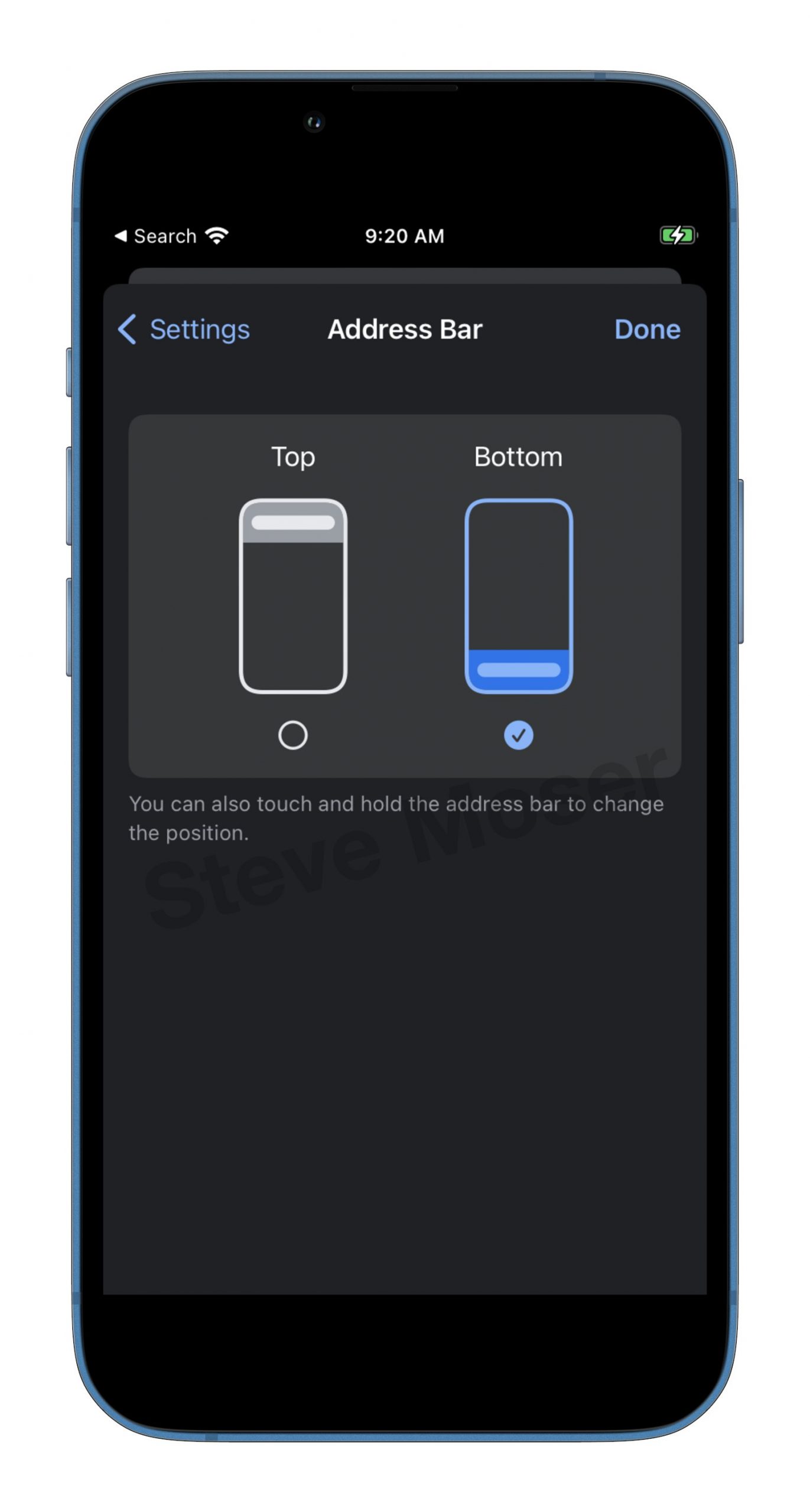
Google Chrome introduced to relocate the address bar to the bottom of screen in iOS
A beta version of Google Chrome for iOS has introduced the option to relocate the address bar to the bottom of the screen, spotted by MacRumors contributor Steve Moserm. This feature offers users a convenient adjustment, allowing them to bring the address bar within easy reach of their thumb. It’s worth noting, however, that this move comes two years after Apple had already made the URL bar at the bottom of Safari with the release of iOS 15.
You can explore more screenshots in this twitter post.
Asahi
waithaw at 2023年09月12日 10:00:00
AI website builders UI/UX designers should try
AI website builders are creating quite a buzz in the world of web design. Recently, I’ve come across some truly impressive ones that have caught my eye. Although we’re not quite at the point where you can simply type out an idea and watch a website magically appear, I have a strong sense that we’re getting closer. Here are the top 7 fantastic AI builder platforms that every UI/UX designer should keep an eye on:
1. Wix AI
Wix AI is perhaps the most user-friendly website builder I’ve encountered. You can pick it up in a day and have your site up and running. What’s more, it’s budget-friendly! And here’s the exciting part – they’re constantly adding new AI features, including text and image creation, background removal, and more. They’re on the verge of launching an AI site builder as well.
2. 10Web
Imagine that AI to set up a WordPress site and then fine-tuning it with the Elementor editor. That’s precisely what this tool offers! The best part? It seamlessly integrates with WordPress, the platform behind nearly half of all websites. It’s a simple and smart solution.
3. Bookmark
Recently, I stumbled upon a new AI website builder that’s brimming with features! It’s a perfect fit for businesses. Not only does it assist with SEO, but it also offers online selling options, generous storage, and detailed analytics.
4. Dora AI
Dora AI is at the forefront of bringing AI to website building. While it’s not available yet, the sneak peeks are quite promising. I’m hopeful that it lives up to its potential as showcased in the videos. You can join the waitlist on their website.
5. Framer AI
Framer AI stands out as one of my favorite website builders. Kudos to the Framer Team for crafting this gem! What sets Framer apart is its ability to not only create websites using AI but also allow you to edit them as if you were working on a Figma file. You can explore it yourself for free on their website.
6. Durable
With Durable, you can literally build your website in just 30 seconds with the power of AI. It’s a perfect solution for those in search of a business or professional site. In my experience, its results are even more impressive than Framer’s. With just a few tweaks, you’ll be ready to go live. This AI builder is arguably one of the most relevant options available.
7. Kleap
Kleap not only builds your website using AI but also assists you in selecting the right words and images. It even helps you track analytics, and its mobile-friendly design is impressive.
These AI website builders are revolutionizing the way designers approach web development. Keep a close watch on these platforms as they continue to evolve and make website creation more accessible and efficient than ever before. You can explore more by clicking the link of each topic.
This is all for now. Hope you enjoy that.
By Asahi
waithaw at 2023年09月05日 10:00:00
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ