OpenAI GPT API(3) Tokenとは
- 2023年5月25日
- AI
今回はOpenAIのTokenについて説明します。
OpenAI API Tokenとは
Tokenはテキスト生成系AIのAPIに使用されます。
画像生成や音声認識系AIのAPIには使用されません。
TextComplrationAPIやChatGPT系のAPIはテキスト生成系AIなので
Tokenの単位で動作します。
またOpenAI APIの利用料金の算出もToken単位でおこなわれてます。
GPTは単語(ワード)単位で動作するのではなく、Token単位で動作します。
Tokenは単語(ワード)単位に近い場合も多いですが、1ワードで1トークンとは限りません。
入力された「文章」をモデルが単語単位や単語をさらに細かく分割してToken単位に変換します。
Tokenは単語(ワード)単位になることもありますし、単語をさらに細かく分割した単位になることもあります。
英語の場合、4-6文字程度で1トークンとなることが多いです。
日本語の場合は基本1文字につき1トークンですが、1文字がさらに分割され複数トークンとなる場合もあります。

上記の文章は6ワードですが、Tokenにすると8トークンです。
色分けされている区切りがToken単位での分割です。
chinese(中国)やnoodle(ラーメン)は1ワードですが、Tokenに変換すると
2つに分割されていることが確認できます。
chineseは「ch」と「inese」に分割され、noodleは「nood」と「le」に分割されています。
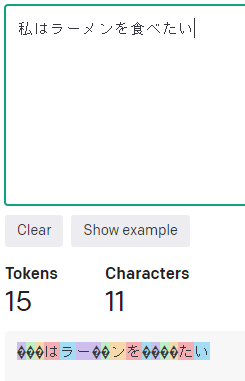
日本語の場合の例です。
基本1文字につき1トークンですが、例えば、「私」は「???」に分割され
「私」1文字で3トークン使用していることが確認できます。
「食べ」はそれぞれ2トークンずつに分割され、合計4トークンですが、
「たい」は1文字1トークンで合計2トークンです。
同じ内容の文章でも英語よりも日本語のほうが使用するトークン数が
多くなる傾向があるようです。
(英語)
I want to eat chinese noodle
→文字数は「28」だがTokenに換算すると「8」トークン使用
(日本語)
私はラーメンを食べたい
→文字数は「11」だがTokenに換算すると「15」トークン使用
このトークンの分割基準はモデルが判断します。
ChatGPTの課金金額は使用するモデルおよびトークン数によって算出されます。
課金金額の算出方法については次回説明します。
OpenAIは入力した文章(プロンプト)のToken数にChatGPTが返却する文章のToken数を
プラスして計算します。
使用するモデルによってToken単位で請求される金額も異なります。
安いモデルもあれば高価なモデルもあります。
GPT-4など高性能なモデルはより高価になります。
各モデルの値段や性能の違いは次回説明します。
Tokenの算出は以下のツールを使用しておこなうことができます。
https://platform.openai.com/tokenizer
OpenAI APIの使用 Token最大値の設定
前回と同じ方法で、最も成功したJazzミュージシャンのトップ10(The top 10 most successful jazz musicians are: )をOpenAIに聞いてみました。
トップ10のJazzミュージシャンのリストがリターンされると予測しますがOpenAIからのレスポンスは以下でした。
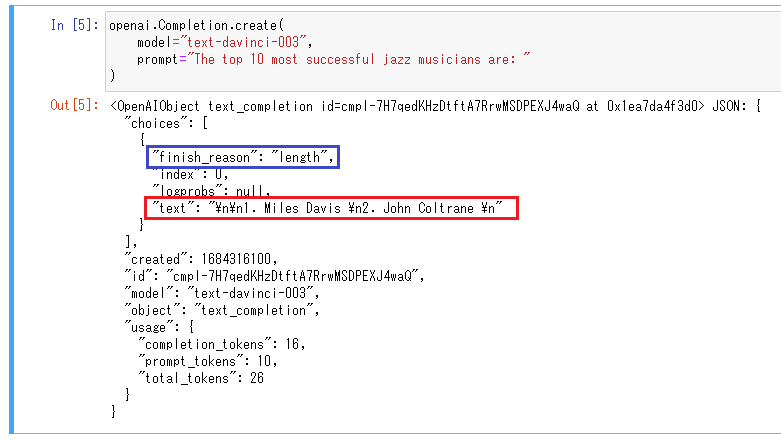
この中のchoices > text (上図の赤枠部分)が返答です。
「\n」は改行コードなので、この箇所では改行が意図されていると読み替えてください。
1位はマイルスデイビス、2位はジョンコルトレーンであることが確認できましたが、3位以下は返答されていません。
なぜ途中で途切れているのかは choices > finish_reason (上図の青枠部分)に原因が記載されています。
今回はfinish_reasonは「length」になっています。
length(長さ)の制限があるためレスポンスが途中で途切れているという意味になります。
公式ドキュメントを確認します。
https://platform.openai.com/docs/api-reference/completions/create
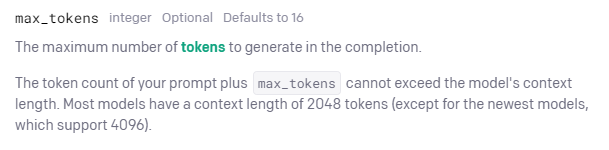
TextComplrationAPIを使用する場合、引数の設定をおこないます。
設定できる引数の中に、max_tokensの設定があります。
max_tokensの設定はオプションで必須ではありません。
今回はmax_tokensを指定しないでTextComplrationAPIを使用しました。
上記の公式ドキュメントによると、max_tokensの設定がない場合、デフォルト値は「16」であると記載されています。
OpenAIの回答が途中で切れた原因としては、token数が16をオーバーしたため、OpenAIからのレスポンスが途中で切れていたのでした。
max_tokensに設定可能な値ですが、
公式ドキュメントでは「ほとんどのモデルは2048トークンまで使用可能です。
最新のモデルは4096までサポートします」と記載されています。
max_tokensの引数の追加をおこない、10倍の160トークンに設定して再度試してみたいと思います。
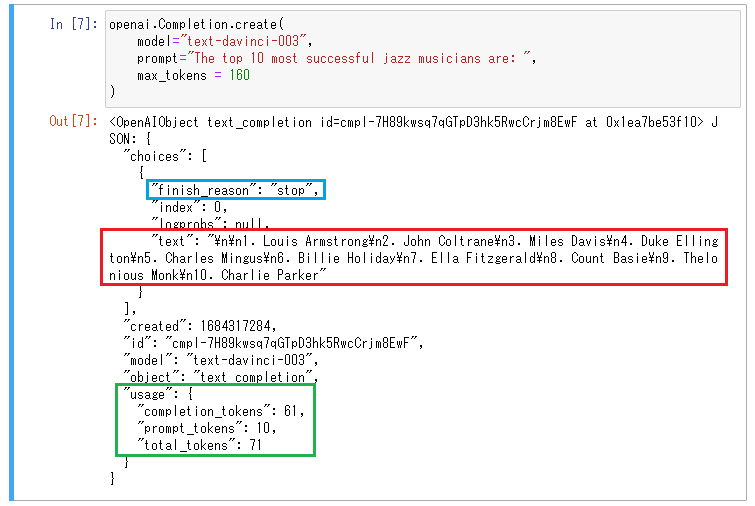
先程の結果とは少し順位が異なりますが、1位から10位まで正しく表示されました(上図の赤枠部分)。
また、前回はfinish_reasonが「length」になっていましたが、今回は「stop」になっています(上図の青枠部分)。
stopはレスポンスが途中で途切れずに正しく停止したことを示しています。
またmax_tokensは160に設定しましたが、
実際に使用されたトークンは
completion_tokens(OpenAIがレスポンスで使用したトークン): 61 と
prompt_tokens(プロンプトに使用したトークン):10 の
合計71トークン使用しました(上図の緑枠部分)。
これまでに使用したトークンの累計および使用した金額はOpenAIにログインした状態で以下の管理画面にアクセスすることで確認ができます。
https://platform.openai.com/account/usage
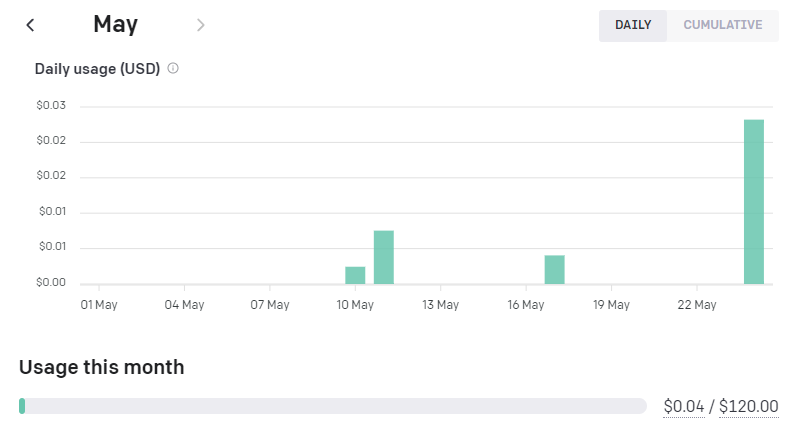
現時点で4セント($0.04)の使用になっていることが確認できました。
次回はOpenAIから提供されているモデルについて説明します。
木曜日担当:nishida
nishida at 2023年05月25日 10:00:00
 大人が楽しめるヒーリング絵本河童のカパと静かな森
大人が楽しめるヒーリング絵本河童のカパと静かな森 パワースポット 日本三大神滝布引の滝
パワースポット 日本三大神滝布引の滝 佐藤・広幸ドイツ魂
佐藤・広幸ドイツ魂 Himeji Castle姫路城
Himeji Castle姫路城 ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜
ボイドタイムお知らせアプリVoid Time 〜月を無視できない〜 撮った写真をカレンダーに撮りカレ
撮った写真をカレンダーに撮りカレ